
The source has a design mistake, in that there is no type unichar for Unicode character. Instead, Unicode strings are carried around in UTF-8, together with an array that gives the lengths of the substrings that represent the individual Unicode characters. This causes code and dictionary bloat, slows down the program, and causes worse OCR performance.
The software has a design mistake in that it talks about "language" where no language is involved. Recognition goes in two stages: first recognize the individual symbols, then improve the recognition using context information. The first stage should not use any language information (but might want font information).
The dictionary files involve nonportable binary data.
Download tesseract-2.01.tar.gz and the small patch tesseract-2.01.patch1.tar.gz, and compile.
Go to a testdirectory, and
It turns out that tesseract only wants input in tiff format, but convert from ImageMagick will convert other formats to tiff.% ln -s path-to-tessdata-dir tessdata % export TESSDATA_PREFIX=./
The first invocation
fails. Ach - it wants some irrelevant data, and these are not in the same tar file. Also download tesseract-2.00.eng.tar.gz and install that. Now try this on a picture with large, very clear text, not precisely horizontal:% tesseract somepict.tiff somepict Unable to load unicharset file eng.unicharset
% tesseract p13a.tiff p13a Tesseract Open Source OCR Engine % cat p13a.txt KINDE mabino ku oro 6 aneno wang acel cal maleng i kira bu muweco i wi lu] ma huk mung,eyire ku ng,inge ma: <<pkawa maju kwo i iye». Cal ne rye nyele mubino kam- wonyo yedi. Cal ne eni eno. ]uyer0 i kitabu nia: <<NyeI0 bemwonyo cam migi zo ma- lungu manang,u igi nyanok de ginyamu ungo. Macen gi gam giwutho di karacelo man giwutho dui abusiel pi kuro cam uregire kudi igi.» Wiya ugam uparu lembe lee iwi wotho mi lum kare ma ot umbe i iye,e agam ating,0 kalamu mi yen mi rangi man arie- do wang,ay0 `mabilubo kuca. Cal para ne makw0ng,a ubino kumae:
Not bad at all, but with some errors. Apart from t read as r and l read as ] or I and J read as ] and « read as << (where » is recognized correctly) and missing circumflex on î, there are many o's that are read as 0 - surprising, since 0 tends to be taller than o (and is less likely in a word). A blot on the paper is read as `.
Tesseract can be trained for a specific language. (In reality training for a specific font seems more important.)
Let us try, following the instructions at TrainingTesseract.
The tesseract command yields a file with the recognized letters and the coordinates of the boxes around them. The edit command must correct the symbol in the box, or the box coordinates, or merge or split boxes. Here, for the two occurrences of `giwutho' the boxes given are for g-i-w-t-h-o, with a very wide box labeled `w'. Note that the text in this box file contains other errors than the file p13a.txt we got earlier.% tesseract p13a.tiff p13a batch.nochop makebox % mv p13a.txt p13a.box % emacs p13a.box ... % diff p13a.box~ p13a.box 43c43 < r 156 564 168 588 --- > t 156 564 168 588 58c58 < ] 499 568 509 601 --- > l 499 568 509 601 86,87c86 < < 116 515 125 530 < < 122 516 131 530 --- > « 116 515 131 530 104,105c103 < > 488 520 497 534 < > 493 520 503 534 --- > » 488 520 503 534 ... 152c150 < j 78 398 95 437 --- > J 78 398 95 437 ... 174,175c171,172 < I 500 411 511 444 < 0 511 410 531 431 --- > l 500 411 511 444 > o 511 410 531 431 244c241,242 < w 75 301 123 321 --- > w 75 301 103 321 > u 104 301 123 321 249c247 < i 212 301 224 332 --- > î 212 301 224 332 ...
Now train using
% tesseract p13a.tiff junk nobatch box.train
Tesseract Open Source OCR Engine
Box file format error on line 442 ignored
APPLY_BOXES:
Boxes read from boxfile: 441
Initially labelled blobs: 437 in 12 rows
Box failures detected: 4
Duped blobs for rebalance: 4
"K" has fewest samples: 1
Total unlabelled words: 3
Final labelled words: 441
Generating training data
TRAINING ... Font name = UnknownFont.
Generated training data for 441 blobs
% mftraining *.tr
Reading p13a.tr ...
Writing Merged Microfeat ...Done!
% cntraining *.tr
Reading p13a.tr ...
Clustering ...
FreeTrainingSamples...
Writing normproto ...
% unicharset_extractor *.box
Extracting unicharset from p13a.box
Wrote unicharset file ./unicharset.
% cp unicharset tessdata/xxx.unicharset
% cp pffmtable tessdata/xxx.pffmtable
% cp inttemp tessdata/xxx.inttemp
% cp normproto tessdata/xxx.normproto
There seem to be 4 more data files, but I have no content for them. Not creating these, or leaving them empty, fails:
% tesseract p13a.tiff p13a -l xxx Could not open file, ./tessdata/xxx.freq-dawg % touch ./tessdata/xxx.freq-dawg % tesseract p13a.tiff p13a -l xxx Error: Illegal malloc request size! Fatal error: No error trap defined! Signal_termination_handler called with signal 2001 Signal_exit 30 SIGNAL ABORT. LocCode: 3 SignalCode: 3
Create an empty word list, and convert that to a dawg.
Hmm. What is wrong? Read source. Fix bug. Apply patch1. Try again.% echo > emptylist % wordlist2dawg emptylist empty-dawg Building DAWG from word list in file, 'emptylist' Compacting the DAWG Compacting node from 0 to 1000000 (0) Segmentation fault
Hmm. What is wrong? Read source. Fix bug. Apply patch2. Try again.% wordlist2dawg emptylist empty-dawg Building DAWG from word list in file, 'emptylist' Compacting the DAWG Compacting node from 0 to 1000000 (0) Writing squished DAWG file, 'empty-dawg' 0 nodes in DAWG 0 edges in DAWG % cp empty-dawg tessdata/xxx.freq-dawg % cp empty-dawg tessdata/xxx.word-dawg % touch tessdata/xxx.user-words tessdata/xxx.DangAmbigs % tesseract p13a.tiff p13a -l xxx Error: Illegal malloc request size! Fatal error: No error trap defined! Signal_termination_handler called with signal 2001 Signal_exit 30 SIGNAL ABORT. LocCode: 3 SignalCode: 3
It turns out that reading the binary file intproto (that has a copy of in-memory data structures) is done in chunks of different sizes than the writing, and due to alignment and padding that fails. Patch intproto.cpp so as to read and write in precisely the same way. Apply patch3. Try again.% tesseract p13a.tiff p13a -l xxx Bad read of inttemp! Bad read of inttemp! ...
Almost perfect. Only the blot, that looks like a `, is now seen as an N, probably because ` does not occur in the allowed unicharset, and tesseract does not want to ignore it. Further tests on other pages from the same book are very successful. The only flaws are misrecognitions of all characters that do not occur in unicharset because they happened to be absent in the training material.% tesseract p13a.tiff p13a -l xxx Tesseract Open Source OCR Engine % cat p13a.txt KINDE mabino ku oro 6 aneno wang acel cal maleng i kita bu muweco i wi lul ma huk mung,eyire ku ng,inge ma: «pkawa maju kwo i iye». Cal ne tye nyele mubino kam- wonyo yedi. Cal ne eni eno. Juyero i kitabu nia: «Nyelo bemwonyo cam migi zo ma- lungu manang,u igi nyanok de ginyamu ungo. Macen gi gam giwutho dî karacelo man giwutho dui abusiel pi kuro cam uregire kudi igi.» Wiya ugam uparu lembe lee iwi wotho mi lum kare ma ot umbe i iye,e agam ating,o kalamu mi yen mi rangi man arie- do wang,ayo Nmabilubo kuca. Cal para ne makwong,a ubino kumae:
(Maybe that is a problem in the current setup. If I want to digitize a book, I do not know what symbols will occur, unless I first carefully scan the entire book by eyesight. The training should improve the recognition of the symbols that occurred in the training material, but should not prevent recognition of other symbols, that were recognized correctly before the training.)
After digitizing a number of pages:
Hmm. All these images were made in the same way, should have the same format. Maybe this page is slightly larger than other pages. Inspection of the source does not show any reason why anything would be wrong with 16 bpp. Added 16 in the list of acceptable values for bpp: apply patch5. Try again. A flawless result.% tesseract p15b.tiff p15b -l xxx Tesseract Open Source OCR Engine check_legal_image_size:Error:Only 1,2,4,5,6,8 bpp are supported:16 Segmentation fault
n1.G 11- A.f`g,·GlGid va
EGT1 gc:w»t1·1"·"1:2-····· GJ? ]·g:>·G-I
g:1:·< J-t:G zGx1d.G 1:G11G1
vGr1, Z.ï(j.E.. tI lcc
]fl`i..# 1: ;fE`ï_j:r1 GJ:
z`i;G»J:1 VG11. Gc>1r1Gr·`_:;»<
% rm -r tesseract-2.01a rm: remove write-protected regular file `tesseract-2.01a/ccstruct/pageres.h'? y rm: remove write-protected regular file `tesseract-2.01a/tessdata/nld.DangAmbigs'? ^C % rm -rf tesseract-2.01a
The code I have seen so far is rather fragile. It is easy to provoke crashes. Insufficient error checking.
The code is cluttered up with lots of debugging statements.
The dictionary code uses utf-8 internally in a very clumsy way, treating unicode characters as strings of unknown length. More more convenient (and much more efficient) is to use a type unichar (16 or 32 bits), and have the dictionary structures something like
/*
* A dawg represents a directed graph in the following way:
* A graph vertex (node) is a consecutive subarray
* of the array of edges. This subarray has two parts:
* first the outedges (forward), then the inedges (!forward).
* The node ends with the is_last flag.
* The other endpoint of the edge is given by the next field.
*
* The graph has content: each edge is labelled with a char c,
* and an edge can be marked with the is_wordend flag.
* All words start at node 0.
*
* Empty (unused) array elements are recognized by is_empty()
* and set by set_empty_edge(). E.g., are entirely 0.
*/
typedef unsigned short int unichar;
typedef unsigned int boolean;
typedef unsigned long node_ref; /* index in array */
struct edge {
unichar c; /* can also be 32 bits */
boolean is_last:1;
boolean is_wordend:1;
boolean is_forward:1;
node_ref next:45; /* 29 is enough */
};
struct dawg {
struct edge *edges; /* array */
int max_num_edges; /* size of array */
int reserved_edges;
};
There does not seem to be a description of the invocation of tesseract.% tesseract foo.tiff foo % tesseract foo.tiff foo -l language % tesseract foo.tiff foo batch.nochop makebox % tesseract foo.tiff foo -l xxx batch.nochop makebox % tesseract foo.tiff junk nobatch box.train
Clearly, the -l xxx switch selects the eight files xxx.* corresponding to language xxx in the tessdata directory.
It is possible to provoke a usage message:
% tesseract tesseract:Error:Usage:./tesseract imagename outputbase [-l lang] [configfile [[+|-]varfile]...] Signal_exit 25 ABORT. LocCode: 3 AbortCode: 0
The image is supposed to be a TIFF file, regardless of the extension. However, if there is no extension, the program segfaults. (Fixed by patch6.)
% cat batch # No content needed as all defaults are correct. % cat batch.nochop chop_enable 0 enable_assoc 0 % cat nobatch display_text 0 % cat matdemo EnableAdaptiveDebugger 1 MatchDebugFlags 6 MatcherDebugLevel 1 % cat segdemo display_splits 0 display_all_words 1 display_all_blobs 1 display_segmentations 2 display_ratings 1
Apparently there are variables that one can set. So far there is no documentation other than the source. In the source these can be recognized by the declarations make_toggle_var, make_int_var, make_float_var.
More variables that can be set. In the source these can be recognized by EXTERN BOOL_VAR, INT_VAR, STRING_VAR, double_VAR. Lots and lots of those.% cat api_config tessedit_zero_rejection T % cat makebox tessedit_create_boxfile 1 % cat unlv tessedit_write_unlv 1 tessedit_write_output 0 tessedit_write_txt_map 0 % cat inter interactive_mode T edit_variables T tessedit_draw_words T tessedit_draw_outwords T % cat box.train file_type .bl tessedit_use_nn F textord_fast_pitch_test T tessedit_single_match 0 newcp_ratings_on 0 tessedit_zero_rejection T tessedit_minimal_rejection F tessedit_write_rep_codes F ignore_weird_blocks F tessedit_tweaking_tess_vars T il1_adaption_test 1 edges_children_fix T edges_childarea 0.65 edges_boxarea 0.9 tessedit_resegment_from_boxes T tessedit_train_from_boxes T
(If the environment variable is not set, and nothing was predefined at compilation time, some obscure code will use the environment variable PATH and the name of the executable in an attempt to find the directory containing the executable, in the hope that the data files might be nearby.)
The environment variables SBADDR, WMSHM, DISP are used by start_sbdaemon() in viewer/grphshm.cpp.
The environment variable DISPLAY is used in ccutil/debugwin.cpp when setting up a remote shell for a debugging window.
The otherwise unused ccmain/tesseractfull.cc gives an example invocation as module in a larger program - roughly: specify the language and the image, and get the text.
#include "baseapi.h"
char* run_tesseract(const char* language,
const unsigned char* imagedata,
int bytes_per_pixel, int bytes_per_line,
int width, int height) {
TessBaseAPI::InitWithLanguage(NULL, NULL, language, NULL, false, 0, NULL);
char* text =
TessBaseAPI::TesseractRect(imagedata, bytes_per_pixel, bytes_per_line,
0, 0, width, height);
TessBaseAPI::End();
return text;
}
The actual main program ccmain/tesseractmain.cpp first calls InitWithLanguage, then reads the provided TIFF image, then calls TesseractRectBoxes in case tessedit_create_boxfile was set (which is done by configs/makebox) and calls TesseractRect otherwise, and then writes the results.
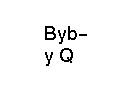
Tesseract reads the "Byb-", "y Q" as
which is not very accurate, but more surprising is that the boxes it finds% tesseract trigger.tiff trigger Tesseract Open Source OCR Engine % cat trigger.txt Bvb" V0
are given by% tesseract trigger.tiff trigger batch.nochop makebox Tesseract Open Source OCR Engine % cat trigger.txt B 44 40 57 56 v 57 40 67 56 b 67 46 78 62 " 78 54 88 58 V 44 16 54 32 0 59 25 74 41
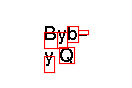
aeb@cwi.nl